Overview page of vishia for emC |
|
C or C++, that is the quest ? |
|
A proposal for a proper organization of files, used in emC |
|
Operation System and Hardware Abstraction / Adaption Layer usage |
|
Adaption of target specific compiler properties for compatible usage |
|
Adaption of settings for the application on different platforms |
|
Exception handling, assertion, stack trace in log |
|
Basic data for each instance, concept |
1. Delimitation, for whom is emC interesting
If you use C++ for PC programming, don’t read this article, it has no new values for you. Use the newest C++ features acordingly to standards. I’m also not using emC for that, I write my PC programs in Java.
If you have on your powerful embedded platform any RTOS (Real Time Operation System), the cycle times are not too fast (> 1 ms), then you may have your programming environment which should be used, preffered it’s C++. You may have a small look to this article, because at all you may also program on faster cycle times without RTOS, and you have interest on Embedded Programming. But it is not necessary for you.
Estimatet 50% of all embedded platforms are still programmed in C instead C++. These can be legacy projects, traditional policies, habit, etc. Then it’s stronly recommended to think about programming in C++, because usual all embedded compiler support it. You may have the problem of refactoring your sources. You should use modern concepts for example a proper Exception Handling instead manual programmed work arrounds on unexpected situations. But, because not all may be sufficient in modern C++, you don’t know how to decide. Then the best thing for you to do is to look into the emC concept. It should have the expected solutions.
If you have no legacies, but you should program not too expensive controllers in a fast cycle time, then anyway you should think about such concepts as Exception Handling and test code on PC. You may see limits using C++. The execution of simple codes is efficient, don’t need extra machine code time just because of C++, that’s really wrong. But for example C++ exception handling is costly. It is proper for PCs with high clock and longer by the way thread switching times. It is not suitable for fast cycles (less than 1 ms, otherwise 20..50 µs are possible). For that the emC concept should be exactly that what’s helping.
2. Ordinary development in C and C++ on PC and on embedded hardware

Development on PC uses usual a proper IDE (Integrated Software Environment) which helps you to write your own sources. A large set of header files and related libraries are responsible to the adaption to the operation system.
look also on the

On embedded hardware the standard libraries have often not such an importance,
because printf is not the goal, instead access to hardware.
For hardware access either some headers are pre-defined from the producer of the hardware or from a related system house, or you can also write your own, based on the register addresses and definitions in the controller’s manual.
With some years experience with your hardware you will get "your system".
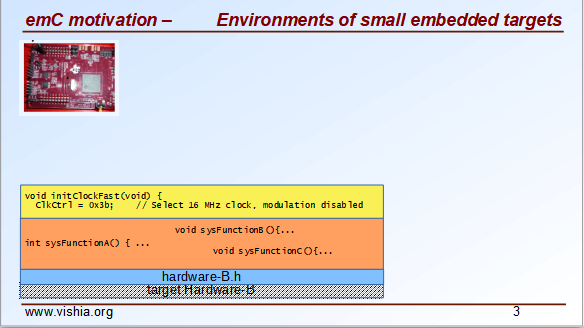
On the other hand you can use a given basic system from the controller producer which contains all. This may be a RTOS ("real time operation system") which is usual a good decision to use. But for small hardware often a system is offered, which may sometimes have only the nature of examples, which may be or not adapted by your own.
But for this the thinking is predetermined by the given system.
⇒ All of these approaches lead toward specialization.
-
Your target sources cannot be run or needs special adaptions for test on PC.
-
If you want to change your platform, some till all should be written newly, or at least refactored.
3. Approach to test all target software on PC
See also the video which continues the video above:
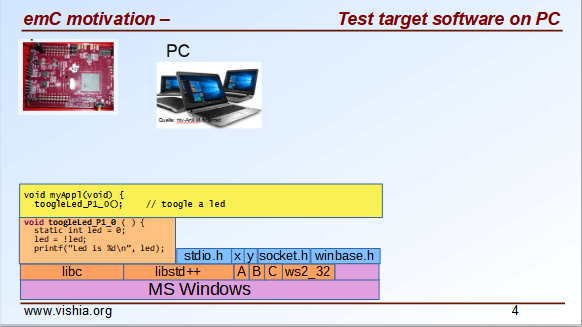
C and also C++ is by itself platform independent. That was one of the approaches in Bell Laboratory in the 60th and 70th, of course firstly with the eyes of the large and different computers on that time. Details of programming styles on different platforms, special constructs of one or the other producer of tools prevent this approach. It is not a quest of the capabilities of different platforms, it is often unnecessary details.
The image right shows, if you have a LED on your hardware which should be toogle, you can of course emulate this behavior with a proper (here very simple) output on PC. Your application program should be independent of your target properties or the target compiler, should be able to compile in any system.
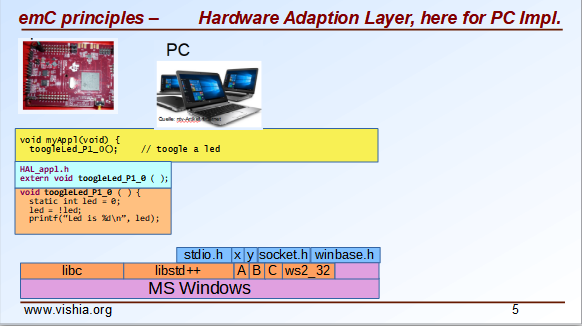
You need a file for "Hardware Abstraction Layer" which contains a function call to your hardware. The implementation can now used independent of your target with a proper PC emulation.
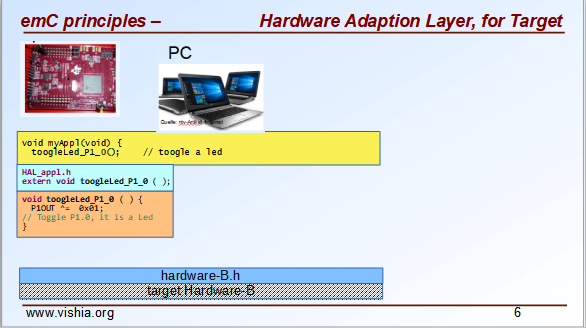
... and of course you can use exactly the same application sources also for the target. Only the Hardware Adaption Layer should be changed.
If you ask about: "is it optimized to have an extra call only for the implementation, the call needs calculation time" then there are two answers:
-
Your compilation should use the highest optimizing level, "over all sources". then the linker removes unnecessary calls. Often they are proper able to detect. You should not consider optimizations on the machine code in your software technology itself underestimating the power of modern compilers.
-
Sometimes
inlineoperations are helpfully. You can use the search path. Write header files with the same name more as one for each target, and store it in the specific directories which are found by the target compiler specific include path.
If you follow the image above, the software is divided firstly in
-
target independent parts (green) for the bulk of your application
-
target depending parts, blue and violet.
The Hardware Abstraction Layer, it is the header file(s), is target independent. Their implementation should be done special for any target, it is the Adaption Layer.
But secondly the software is also divided in
-
application specific parts
-
common usable parts, whereas also parts of a Hardware Abstraction header file(s) may be common usable.
It may be interesting that the main organization of the application is hardware depending. It contains specific hardware initialization calls, etc, but also the interrupt routine frames.
Refer also to OSHAL/HAL.html
+-src
+-docs
+-test
+-main
+-cpp
+-MyApplication ... application sources
| +-TargetX ... apl specificas for the platform X
| | +-main.c ... main is appl & platform specific
| | +-applstdef.h ... defines target specific charateristics
| | +-TargetAdapXY.c ... Hardware Adaption applic specific
| +-TargetY ... another target
| | +-main.c
| | +-applstdef.h
| | +-TargetAdapXY.c
| +-test_PC ... all for PC test
| | +-main.c
| | +-applstdef.h
| | +-TargetEmulation.c .
| +-ApplTarget.h ... header defines the applic specific hw abstraction
| +-Applic.c ... application sources
| +-Subdir ... application source components
|
+-MyApplicGroup ... Contains also common sources for applications
|
+-src_emC ... The emC sources----
|
+-PlatformX ... Specific sources for a platform
| contains the hw implementation layer
+-PlatformY ... Other platforms
Of course these different files should be well organized. As basic a so named maven tree can be used, a preferred proposal. See also
As you see the application itself contains the application specific and target specific sources
in adequate sub directories.
Where as application independent, common used sources are beside. All is in the src/main/cpp folder.
The parallel existing src/test/cpp/MyApplication/* is for the test.
Of course you need a specific IDE with its project files for each target. That is presented also in the link above.
The video (link an chapter start) shows also a running example for a simple blinking led on PC test and a MSP430 target hardware.
The first goal of emC is to provide a compatible writing style of sources for each platform. It should be a putty between different systems for programming.
The different systems may be necessary, for special solutions, but common used parts of the sources should be compatible with all.
4. Refactoring legacy sources towards emC concept
See also: Video: RefactoringLegacy
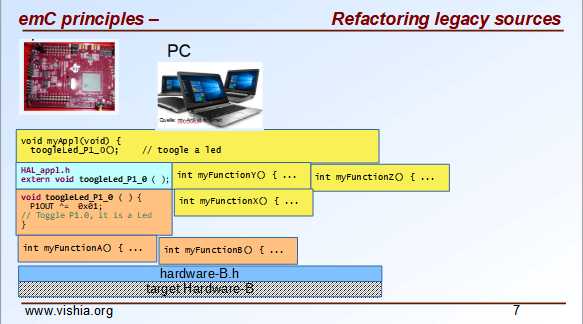
Legacy sources are often very specific to the target hardware. The other one is, they should be refactored.
Don’t worry about refactoring!
-
You should work step by step. Making only one change, But one change can entail some more changes than a complex. You should do it. Make a safety copy before.
-
You should use a compiler which shows all relevant writing errors. This is not the ordinary C compiler. Use C++ for compilation also the C sources, at least during the refactoring. The C++ compiler shows more stupid writing errors.
-
Test any change if possible.
As result you can adapt any functions and data step by step to a better approach:
-
Use Object Orientation style (using
structand related functions) also for C programs. Prevent outstanding static data. Use references instead access to static data inside the functions, independent of the fact how the data are defined in the whole application. -
Divide to platform dependent and independent.
-
Use sub functions, look what’s happen for optimizing levels.
-
Be carefully with optimizing. The optimizing of the compiler is usual error free, but if you have bad constructs such forgotten
volatilewhere it is necessary or non initialized variables, the optimizing will be produces the correct result for this incorrect code, and your result is wrong.
5. May is it possible that given compilation systems are non proper in some cases
This is a carefully formulated question. Look for example to https://en.wikipedia.org/wiki/C_standard_library#Problems_and_workarounds ( seen on 2022-Jan-10)
Buffer overflow vulnerabilities Some functions in the C standard library have been notorious for having buffer overflow vulnerabilities and generally encouraging buggy programming ever since their adoption.[a] The most criticized items are:
....
Error handling
The error handling of the functions in the C standard library is not consistent and sometimes confusing. According to the Linux manual page math_error, "The current (version 2.8) situation under glibc is messy. Most (but not all) functions raise exceptions on errors. Some also set errno. A few functions set errno, but don’t raise an exception. A very few functions do neither."[16]
Of course this quote is related to C language, and the problems are well known. The newest C++ version have never such problems, it is safe. Do you think?
C and also C++ are great ecosystems with many leaks. You should not believe that you are in a safe environment. Some style guides, checking tools and also a 4-eyes review and talks with colleagues and experts help.
If you have a side glance to Java, see also chapter Is C/C++ the best language also for data evaluation on embedded ? Hint to Java: Java is developed with all knowledges of the pitfall of known C and also C++. Java in its basic is safe, whenever the memory can also crash because of stupid programming. Thats why Java is usual unbroken the number one of programming languages, beside some other. C and C++ has the advantages that it is near to machine code, hence the number one for embedded control but also therefore with some pitfalls.
Hence, a proper decision is:
-
Using C/++ for machine near things, that is kernel and embedded.
-
If you have more complex algorithms that cannot be tested in all details and which are written by some people with more or less understanding, use for that parts Java or another safe language. Usual such systems are available for powerful hardware.
-
Do not think, the newest C++ solve all problems.
If some C and C++ ecosystems say there are safe, it may not be true.
The advantage of C and in many cases als of C++ is: You can immediately look what’s happen on machine code execution. And that is your profession as embedded programmer.
6. Main approaches of emC
Here shortly the approaches of emC programming and solutions are named. Details are linked.
All approaches except the portability are independent.
So you can focus firstly to only one approach, first the portability
with the concepts of headers compl_adaption.h and applstdef.h
to see what’s happen and mean.
Then you can try the next one, preferred deal with the Excpetion handling concept.
You can use by the way some implementations for example for String processing (a little bit other for embedded control) and control Function Blocks. If you have Simulink (® Mathworks), you can use even this codes also as S-Functions. In the future I will offer the same C-Functions also in Open Modelica.
The ObjectJc concept may be the last one to explore.
It is usefull for safety and also for inspecting data on your platform,
debugging in run time.
6.1. Portability
Compilers, for C and C++ have often specific properties. Features which are provided from the compiler are often not compatible between compilers. All nice so named 'standards' which are contained in some standard header are often slightly different. Simple self managed header files are sometimes better than using the slightly different headers of the systems. This problems are familiar known for a long time in embedded programming. But also the self written headers of legacy are sometimes different.
emC provides an unique approach firstly with the compl_adaption.h
as central header file to define types and macros in a compatible way between platforms.
This header file should not be application specific,
it should control that the compilation platform is compatible with all other ones.
See chapter Necessity of compl_adaption.h and Base/compl_adaption_h.html.
You can also include there your own legacy type system as also specific type systems
from other platforms to get it compatible.
You can use the C-99 defined standard types,
both by including the stdint.h and limits.h as well as definition
this types standard-conform by yourself. The C-99 types (int32_t etc.)
are not an intrinsic compiler ability, they are only defined in header files
for your compiler suite. But sometimes this header files are not incomplexity,
so an own definition is a proper approach and not standard-violating for your written sources.
emC provides an unique approach secondly with the applstdef.h as central header file
to determine the behavior for all sources.
This file is usual application specific, or for a type of applications,
but it should be placed in the application and target specific directory.
With this file you can adapt the application behavior between platforms.
For example you can use C++ Exception Handling on PC-test to find out really all errors
for example especially memory violations because of slightly faulty handling on pointers.
Then you can switch to a embedded-related Excpetion handling
only using the appropriate applstdef.h for the target platform,
without changing any line of the application source.
Another example is, using the elaborate ObjectJc approach for PC test on runtime
with the possiblity to access symbolic to all data, but switch to a basic behavior
for the ObjectJc for a poor target with less memory.
See chapter What is applstdef_emC.h - necessity for emC and Base/applstdef_emC_h.html
6.2. Appropriate exception handling and assertion
The Exception handling approach is important and better than errno or return error in C.
But the pure C++ exception handling needs a too long time on throw,
not able to use in short time deterministic programs (interrupts, control cycles).
emC offers three forming for exception handling, which is applicable also for fast interrupts.
One is the powerfull C++ exception handling especially also for so named "asynchronous exceptions"
which occurs on memory violations on PC (especially Visual Studio with compiler switch /EHa).
But this may be too slow on embedded control.
The longjmp concept is proven, it is not a goto as some faulty expertices suggest.
The only one problem of longjmp is the incompatibilty with some C++ standard libraries.
But they may be anyway not used for embedded programming.
The third form is, expecting exception free code, only write a log and abort one level. That is proper applicable on a poor target, but after elobaretely tests. Even for this it is possible to switch between the powerful C++ exception for the repeatedly executed PC test and the target without changing the sources. Additonal unused CATCH clauses are automaticly removed by the optimization of the compiler.
The Excpetion Handling offers a so named "stack trace" concept which is very proven in all Java programs. It allows simply to detect the really cause of the exception. Also the kind of working with the "stack trace" is able to switch off without source changing for the poor target.
emC offers a macro ASSERT_emC with a proper message
which is included in the Exception Handling concept.
The assert macro in ordinate C++ programs seems to abort the program
if somewhat is wrong.
Admittedly, I have no experience with this
because I was shocked by it the first time I used and inquired.
I know a really proper behavior of assert form Java.
It throws an special exception, accordingly to the common Exception Handling.
Assertions are a very good and preffered concept for "Design by contract" and test of that. It should be more elaborately used. A abort of execution is not usefull for that.
To control the forming the applstdef_emC.h is the essential header.
6.3. Base features of data - ObjectJc
The approach using a unified base class for all data comes from Java: java.lang.Object.
This class refers a simple type descriptions for realtime type check,
reflection for symbolic access, general possibilities for mutex and lock,
an alternate mechanism for overridden operations safe and in opposite to virtual,
helpfully too for debugging.
ObjectJc doesn’t need to be used for all data, of course (other than in Java).
But it is recommended for essential data.
The applstdef_emC.h controls, which forming of ObjectJc should be used
different for PC test and a poor target (with less hardware resources).
6.4. HAL and OSAL
HAL is the Hardware Adaption Layer, OSAL is the Operation System Adaption Layer. The separation of hardware and operation accesses are essential for portability.
emC offers a strategy for HAL and OSAL, whereby the penetration to hardware register of a controller should be unconditionally efficient, however with breaking of dependencies between application and platform.
6.5. Libraries of algorithm are an attachment
Developer knows by itself the proper algorithms. The emC can help only. It is not the ultimate library collection.
An application which uses the emC approaches can be tested under PC and used for several platforms.
7. Necessity of compl_adaption.h

As the slide shows the C99 types for bit width fixed integer data types are not present overall. One reason is - the tradition. Often used and familiar type identifier are used furthermore. It is also a problem of legacy code maintenance. The other reason: The standard fix width types in C99 like int32_t etc. are not compiler-intrinsic. They are defined only in a special header file stdint.h. Usual this types are defined via typedef. This may be disable compatibility. An int32_t is not compatible with a maybe user defined legacy INT32. This is complicating. Usage of stdint.h is not a sufficient solution. It is too specific and too unflexible.
The compl_adaption.h should be defined and maintained by the user (not by the compiler tool) or by - the emC library guidelines. It can be enhanced by the user’s legacy types in a compatible form. It can include stdint.h if it is convenient for the specific platform - or replace this content.
The compl_adaption.h should be included in all user’s sources, as first one. It should never force a contradiction to other included files, else for specific non changeable system files for example wintypes.h which may be necessary only for adaptions of that operation system. Then the contradictions can be resolves via #undef of disturbing definitions of the system specific afterwords defined things.
System specific include files such as wintypes.h or windows.h should never be included in user’s sources which are not especially for the specified system. It should be also true if some definitions should match the expectiations of the user’s source independent of the specific system.
The compl_adaption.h contains some more usefully definitions, see Base/compl_adaption_h.html.
8. What is applstdef_emC.h - necessity for emC

The applstdef_emC.h should be included for all sources, which uses files from the emC concept. Hence it is not necessary for common driver, only hardware depending, but for user sources. applstdef_emC.h includes compl_adaption.h, only one of this file is necessary to immediately include.
The emC concept offers some "language extensions" for portable programming (multiplatform). That are usual macros, which can be adapted to the platform requirements.
For that the applstdef_emC.h should contain some compiler switches
which can be set also platform specific for an application or application specific.
The example shows the selection of an error or exception handling approach. Generally usage of TRY..CATCH or ASSERT_emC is recommended. The user’s application should not regard about "how to do that", because often the sources should be reuseable (not really for exact this application), or the implementation on different platforms should use different types of exception handling - without adaption of the sources.
The exception handling and its approaches are presented on Base/ThCxtExc_emC.html .
-
Some Variants usage the base class ObjectJc for Reflection and Types are presented on Base/ObjectJc_en.html. It can be a simple base struct for poor platforms, or can contain some more information which characterizes all data (basing on ObjectJc) in a unique way.
-
Reflection usage, presented on Base/ClassJc_en.html can be used with elaborately text information for symbolic access to all data, with a "InspcTargetProxy" concept for symbolic access to a poor target system, or only for a maybe simple type test.
9. Kind of usage of emC sources
The sources are available as LPGL (Lesser Public General License) on Github: TestOrg/GitTestEnv_en.html / https://github.com/JzHartmut. You may have a local git archive via git clone from there, or you can get a zip from Github, or also a specific zip from the vishia page.
Generally you may follow the maven file tree idea in your application,
then the local directory for the emC sources is src/main/cpp/src_emC/*.
But you can have also another organization in your own tree,
then put the emC sources on any local location inside the working tree as copy,
but in unchanged inner directory structure.
It is also preferred to use only a part of the sources, only which is necessary. You should not take a large bulk of unknown stuff in your project. You can work step by step with firstly a few files. Which files that are, you see on examples (TODO article with proper examples).
You should not change the emC sources to adapt it for your own. You should use the original.
Of course you can improve the sources, give feedback, collaborate.
But changes should only be done in a way of common usage. This is the emC concept.
The adaption of the behavior of the sources is done by your own applstdef_emC.h
which should be used as template-copy-adapt.
Of course you can use and adapt all the sources for your own regarding the LPGL license, but then you leaf the emC basic idea.
10. Remarks to C and C++ for embedded control and compiler capabilities
10.1. Using C++ also for embedded control
The language C is established since about 1970 (with UNIX) and has become the most important programming language for embedded control since the 1990th. It has largely supplanted assembly language. What is the benefit of C for that role?
C has a high degree of penetration to machine code. When viewing an instruction in C, it can be obvious what is happening in the machine code. That is the primary thought. Therefore the assembly language could be replaced.
C++ is the further development towards to a high-level language. C++ has some interesting or important features. The proximity to the machine code is not necessarily violated. Hence C++ should be used - not in all features - for embedded programming instead C.
Usage of C++ as a high level language for example for PC application development needs another view. The penetration to machine code is not important, more the obviousness of algorithms and the safety of algorithms. The calculation time as a whole should be optimized. For that other concepts are known too. An intermediate code between the high level language and the implementation (machine) code helps to optimize and assure. Java with its Bytecode and similar languages are such an concept. It may be that these approaches are more appropriate, also for application code on embedded platforms. It means C++ may not be seen as the best of all high level language. It couldn’t be its mission.
The mission of C++ is a better programming for embedded. Why?
-
The C++ compilers have often a more strongly check of syntax. It is better to be able to rely on the fact that after a refactoring without an error message there are really no errors.
-
Machine code produced by C ++ is just as optimal as that of a C compiler, for the same sources or for simple class operations. It is not true that C++ produces more ineffective code.
-
C++ programs using classes are more obviously. The Object Oriented Programming is a very important and powerful approach, which is supported primary from C++.
-
The template mechanism of C++ can also be manageable and helpful.
But what are the stop points using C++ approaches in embedded:
-
Some libraries make extensive use of dynamic data, which often cannot apply to embedded programming.
-
The virtual mechanism is not safe. The virtual pointer is between data. It is sometimes possible to check its consistence, but it is not usual. Long running applications may be more sensitive than a PC program.
Generally an application on PC has usual exact two or three platforms: Windows, Linux and Macintosh. Embedded software has much broader areas of platforms. Additionally often there is a necessacity to run algorithm on different platforms. The platforms are often similar in their basic properties, but differ in details. Often software will be written only for one platform which is in focus. Developer uses their own platform in a blinkered view, concentrate to the specific goal. Because focus of development of C++ is often on PC application use or high end algorithm, developers for simple embedded platforms are mostly on their own.
To improve that situation, emC "embedded multiplatform C/C++" is recommended.
10.2. Disadvantages of C++ - why C is often favored?
Not only statistics, but also real experience shows that C is always present, despite all the advantages of C++. Why is it so? It is the experience of the developers and their managers. It is lack of confidence to C++.
This lack of trust is sometimes true. I will give an example:
In C language a const definition have to be possible to calculate on compile time:
const float factor1 = 3.14159f; const float factor2 = 1.0f/3.14159f;
Both is able to calculate by the compiler. Hence the const values itself can be placed always in the FLASH ROM.
Other in C++. It is possible to write:
const float factor = calculateFromStartupData();
It means the value is not calculated in compile time, but in the startup time depending on other given values. Adequate it is with pointer addresses:
const MyData myData = { ...initializer }; // placed in the FLASH in C
const MyData* const pmyData = & myData; // also in FLASH
const MyData* const pmyData2 = (MyData const*)malloc(...) // error in C
In C++ the last line is not an error, because C++ does not interpret the const to initialized on compile time,
but only as not changeable checked by the compiler in run time. It means it can also be defined with the definition
of the const data location itself, for static const in startup time.
But hence it cannot be located in the FLASH.
It means whether a const is located in FLASH or not depends on several conditions, in C++.
For example especially a const member in a class can be initialized in the constructor,
any time while the software is running.
This feature seems to be sensible for higher level programming thinking.
It is possible, usual, because the memory is usual a RAM (for PC programming).
It means, straight thinking, the request to define a const for the FLASH was forgotten or not in focus in the C++ development.
C++ is usual used for PC, and for PC all is proper.
It means in practice: If you use a C compiler, you will get an error message if a const for the FLASH is not possible.
If you use the C++ compiler, you should check where the memory is, study the map file and consider where the problem is,
You will not get any hints from the compiler. If you are not carefully, some const members are located in RAM,
the program runs well, but you get problems if:
-
The software is faulty (not everything has been tested) and a sensitive data "construct" which (according to you) should be in FLASH is destroyed and the program crashes because it was in RAM, which is not obvious.
-
You have extended the required amount of RAM and wonder about an error message because the RAM segment is overfilled, then look up why, and you realize this unexpected problem. Then you should fix other modules that are already tested and maybe processed by other colleagues or departments.
All these things cannot be happen if you program only in C language, and this is an experience.
C++ has introduced meanwhile a constexpr to help for this feature,
see for example https://www.modernescpp.com/index.php/constexpr-functions
But the problem is:
-
Some compiler for embedded supports only till C++11, in the year 2022.
-
It is not known and familiar by some developer which are C-oriented. It is a complex feature.
-
There is not a back to C possible.
What can help from a view point of simple thinking:
-
Use only C language in your code for such sensitive parts, especially const data definition.
-
You can use the C compiler for that, mixed with C++, using
extern "C"definition possibilities. -
You can use the
extern_Cmacro defined in the emCemC/Base/types_def_common.hheader file, which is included anytime, to work compatible with C and C++ compilation. See also Base/LangExt_en.html#_extern_vs_extern_c_or_extern_ccpp -
You can use also the C++ compiler for these parts if you have checked that the C compiler has no errors for the
constdata. Then also the C++ compiler should place the data in a const segment (can be located in FLASH). But you should check your map file nevertheless. -
Use the C++ compiler for the rest which does not contain such `const`definitions. The C++ compiler is usual better for error checks, also applicable for C code.
-
In sum, some parts of the software should be really C code.
10.3. Compiler capabilities
Often the "new features of modern C++" are topics of some discussions and presentations. But the real important work is done by the compiler tools, often not in the focus.
-
The old known behavior is, that a compiler may optimize the machine code. Optimization is used sometimes, or sometimes not. One other thing is: One compilation unit is translated to an object file, and the content of the object is used as a whole. It means if you have 5 routines in the object file, but only one is really used, all other 4 are unused in your Flash. This is not a topic on PC, or if you have enough Flash memory. It is a topic if you have small poor processors. Hence you are attempt to write small compilation units, tune manually which operations are included for your applications.
-
And that is meanwhile wrong.
For example, Texas Instruments offers in their CodeComposerStudio compiler suite currently two different Output Format for compilations for the executable:
-
legacy COFF
-
eabi (ELF)
Both are currently available. The COFF format is designated as "legacy". It is that one for which the topics above are valid.
The ELF format https://en.wikipedia.org/wiki/Executable_and_Linkable_Format is known since about 20 years, but the decision to use it for an embedded compiler is a specific decision. You should familiar with your used compiler for your specific target.
TODO this topic should be improved time by time maybe by an own article.
10.4. Separation between compiler intrinsic and libraries
The behavior of the compiler is the one side, the content of some header files and given libraries is the other one. Both are two separated, intrinsic not related things. But they are connected by the compiler suite and the formulation of standards for C/++: They come together, without separation.
For the standards, also the libraries and headers are relevant. Because they determine the behavior for usage. That is one approach.
But as embedded programmer, you should separate. You should known your compiler, its behavior and its intrinsic, and you should decide which standards from headers and libraries you want to use really.
The old C approach from Kernighan and Richie and the world of UNIX has had the "Job" approach:
Run a job, get inputs and outputs, pipes, printf("Hello World\n); and such.
The approach of PC programming is often graphic IDEs.
But the approach of embedded control (as well as also Kernel programming)
is, deal with the hardware. That is different.
On embedded control you don’t need printf firstly, you need access to an analog output port.
It may be you never need printf.
You need slight conversion routines for texts for simple numeric presentation
if you have an ASCII monitor access, not the capability of a standard for text processing.
10.5. Is C/C++ the best language also for data evaluation on embedded ? Hint to Java
C and also C++ are favored for access to hardware and manual optimizing of machine code for very short calculation times. But C and also C++ has some pitfalls from its history. Look at a simple example:
ExmplClass* myClass = new ExmplClass(); (myClass+1)->set(456);
This is well compiled C++ code with gcc 10.2.0 with options
gcc -c -x c++ -std=c++20
Also the C++-20 standard does not prevent such a faulty code. The problem may be well visible in the statements one after another: With myClass+1 the pointer is changed to an address exactly after the allocated data. Any usage may disturb important data, not obviously, as side effect. This is valid C++. The error may not be obviously if the error is the result of a change that has not been fully thought out, and it is dispersed in several modules.
Such pitfalls are a result of a simple definition of handling of pointers in the earlier C from the 1970th. Nevertheless this pointer arithmetic as well as the possibility of crazy casts is possible also in the newest C++. Some will be detect by check tools, some are forbidden by program style guides, but the compiler accept it.
While development of the programming language Java in the 1990th such pitfalls of C/++ were observed and regarded. Java was designed as a safe programming language. Especially problems of allocated memory are solved too.
Hence Java is a safe programming language. The myth "Java is slow" is false. Java runs on many server with requests to fast response time. Java is just not suitable for immediate hardware access, to controller (memory mapped) peripheral register etc. For that C/++ is necessary (because another languages is not popular).
But it should be thought about Java usage for data evaluation on embedded. One address for that is https://www.aicas.com/wp/products-services/jamaicavm/
For PC application programming anytime Java is the better approach in comparison to C++!
Some details on the emC let adumbrate the influence of Java.
11. HAL - Hardware Adaption Layer - and file arrangement for embedded targets
An application should divided to
-
a) The core application, platform independent, without source changes able to run as a whole or as modules in unit test also on the PC.
-
b) The hardware driver, often provided by the producer of the controller, without changes respectively independent of the application.
-
c) An intermediate layer, the Hardware Adaption Layer.
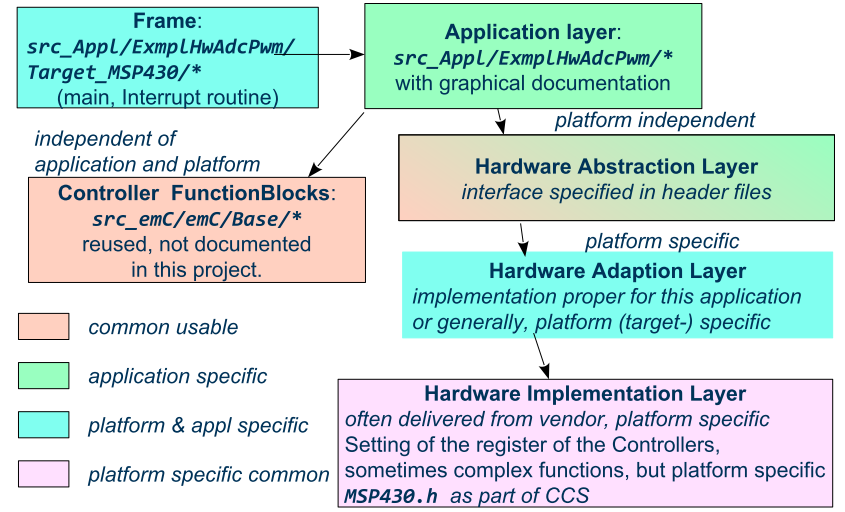
The image above shows general components of an application. Additional, left side, are shown:
-
d) The main application organization with the C
main()routine and the frame routines for interrupts. These are target depending too, because themain()should organize some specific initializings and configuration of the interrupt routines. -
e) Common library functionality, here presented as part of emC but often user-specific but not application specific.
The image shows the
-
f) interface between the application and the HAL as Hardware Abstraction Interface
The points a), e) and f) are platform-independent. f) are either C-language prototypes to call hardware operations, specific inlines which works with references to the hardware register or C++ class definitions without its implementation. The implementation of the C++ classes as well as the C-operations are target/platform specific as part of the c), the HAL.
The HAL is both, application and target specific. Why is it also application-specific? Some parts may be universal, for more as one application. But usually there is no standard possible in a time of applications developement. Often the f) Hardware Abstraction Interface is oriented to the needs of one application or some specific applications, and the HAL should implement it.
The b), the so named Hardware Representation Layer should be as possible as independent of the application(s), originally from the hardware supplier, but often though adapted by the application system developer. In its pure form it should be delivered from the hardware supplier, but often it should be tuned. The Hardware Representation Layer contains access routines to the controller peripheral register and maybe more comprehensive driver (for example for Ethernet communication protocols) which are provided. But also the c) HAL can access immediately the controller registers. But it should use definitions from the Hardware Representation Layer for the access.
12. File folder organization
A maven-like file tree is recommended, though maven itself (https://en.wikipedia.org/wiki/Apache_Maven) is not preferred to use. But this tree has advantages for separation of test and main-application, and components:
Source/Build-Directory, "Sandbox"
|
+-build ... maybe link to temporary location, build results
|
+ IDE ... fast access from root to the Development tools
|
+ src
+-docs ... some documentation outside of the sources
+-test ... some sources and organization for tests
|
+-main ... the main sources of the application
|
+-cpp ... C/C++ sources
+-src_emC ... emC sources
+-ModuleLibXYZ ... some more application independent moduls
|
+-Application ... application sources, maybe with sub folder structure
| |
| +-HAL_xyz.h ... Header for HAL definition, the Hardware Adaption Interface
| |
| +-Application_Modules ... Sub folders
| |
| +-HAL_Target_A ... Sub folder for the HAL for Target A
| +-HAL_Target_B ... Sub folder for the HAL for Target B
| +-..... contains main() and interrupt frames()
|
+-Platform_A
| +- maybe with sub folder
+-Platform_B
|
etc.
-
The
Platform_…files are b), the Hardware Representaion Layer. It should have the own version management. -
As well as
src_emCand some user specific library modules with its own Version manangement. -
The
Applicationwith all its HAL folder should store as one version management bundle (can have sub projects maybe). -
The test accesses ../main/cpp/Application, with its own version management. The structure of the test folder is also a tree, well complex and structured.
-
Build files and IDEs are part of the application. But the organization of the build can be separated in the shown
IDEfolder, for immediately access (not deep in sub trees). Note: file system links and links as property of the IDE can be used.